这次不造轮子,写写文章。
最近想把自己的 blog 整理到 github 上,但由于其中依赖了一些主题以及插件,这时候 git submodule 就能很好的处理这种情况了。
submodule 是什么?
submodule 顾名思义,子模块。在一个项目依赖其他 git 上的模块时就很有用处了。
以我自己这次修改做例子:
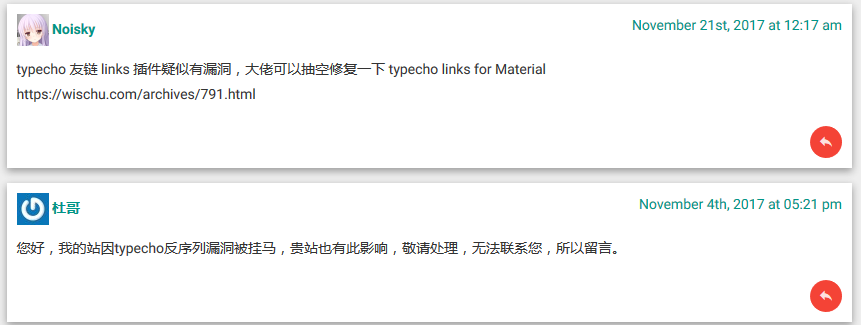
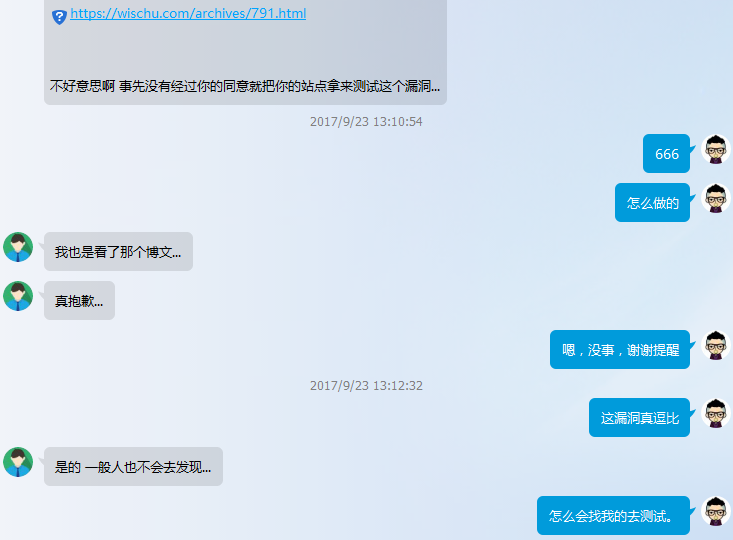
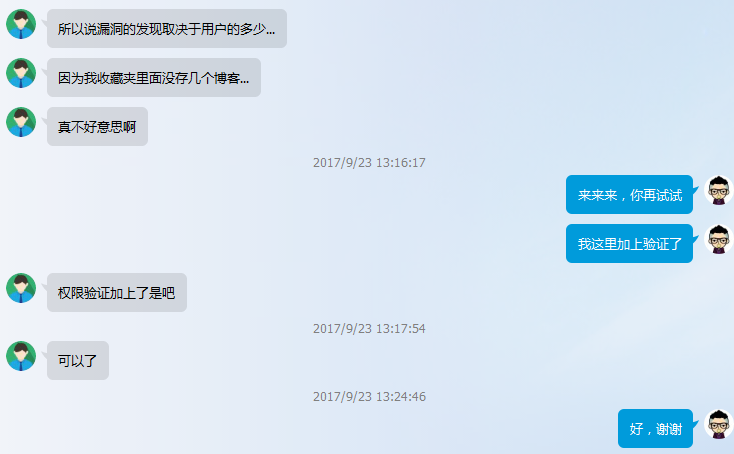
我的 typecho 博客 依赖了 主题 typecho_material_theme 和 插件 Links_for_Material_Theme
那写下来就写写整个过程。
冻手不?冻手
准备
动手
开始增加子模块(最后为路径)
cd typecho
git submodule add git@github.com:HanSon/typecho_material_theme.git usr/theme/typecho_material_theme
git submodule add git@github.com:HanSon/Links_for_Material_Theme.git usr/theme/Links
这时候应该能看到开始对两个库 clone 中,查看一下 git status , 应该能看到修改的有多了两个库,以及 .gitmodules 的修改
git status
然后我们来提交到 github 中
git commit -am "增加子模块"
git push origin master
这时就已经成功提交到 github 上了,我们来看看 github 上是如何显示 submodule 的

可以看到多了两个不一样的图标,点击自动跳转去该仓库的地址(@ 后面代表的是 commit id)
来 pull
git clone https://github.com/HanSon/my-blog.git
cd my-blog
pull 完发现只剩下文件夹,submodule 并没有内容,需要先初始化 submodule 并且 update
git submodule init
git submodule update
这时候就发现 submodule 的内容已经 pull 下来了!
如果更新了 submodule , project 应该如何跟着更新?
- 按需更新。 去到相对应的 submodule 目录执行
git pull origin master 即可。 - 简单粗暴,全部更新。
git submodule foreach git pull origin master
这次给我的博客加上了播放哈林摇的功能 http://hanc.cc

你还可以把上图的 Let's party 拖到书签栏,然后访问你想要摇的网站,点击刚保存的书签进行摇一下。
PS:上面所述为实操后凭记忆记下来的,如有遗漏欢迎补充

这次不造轮子,写写文章。
最近想把自己的 blog 整理到 github 上,但由于其中依赖了一些主题以及插件,这时候 git submodule 就能很好的处理这种情况了。
submodule 是什么?
submodule 顾名思义,子模块。在一个项目依赖其他 git 上的模块时就很有用处了。
以我自己这次修改做例子:
我的 typecho 博客 依赖了 主题 typecho_material_theme 和 插件 Links_for_Material_Theme
那写下来就写写整个过程。
冻手不?冻手
准备
动手
开始增加子模块(最后为路径)
cd typecho
git submodule add git@github.com:HanSon/typecho_material_theme.git usr/theme/typecho_material_theme
git submodule add git@github.com:HanSon/Links_for_Material_Theme.git usr/theme/Links
这时候应该能看到开始对两个库 clone 中,查看一下 git status , 应该能看到修改的有多了两个库,以及 .gitmodules 的修改
git status
然后我们来提交到 github 中
git commit -am "增加子模块"
git push origin master
这时就已经成功提交到 github 上了,我们来看看 github 上是如何显示 submodule 的
可以看到多了两个不一样的图标,点击自动跳转去该仓库的地址(@ 后面代表的是 commit id)
来 pull
git clone https://github.com/HanSon/my-blog.git
cd my-blog
pull 完发现只剩下文件夹,submodule 并没有内容,需要先初始化 submodule 并且 update
git submodule init
git submodule update
这时候就发现 submodule 的内容已经 pull 下来了!
如果更新了 submodule , project 应该如何跟着更新?
- 按需更新。 去到相对应的 submodule 目录执行
git pull origin master 即可。 - 简单粗暴,全部更新。
git submodule foreach git pull origin master
这次给我的博客加上了播放哈林摇的功能 http://hanc.cc
你还可以把上图的 Let's party 拖到书签栏,然后访问你想要摇的网站,点击刚保存的书签进行摇一下。
PS:上面所述为实操后凭记忆记下来的,如有遗漏欢迎补充